RAG (Retrieval Augmented Generation) — это метод работы с языковыми моделями, который сочетает поиск и генерацию. Сначала система находит релевантную информацию во внешних источниках, затем языковая модель использует её для формирования ответа — более точного и основанного на фактах. Такой подход помогает отвечать не только на основе встроенных знаний модели, но и с учётом внешней информации.
Генеративные модели обучаются на текстовых корпусах. Объём и качество этих материалов зависят от доступных источников: открытых баз, статей, публикаций в интернете и социальных сетях.
RAG даёт доступ к дополнительным источникам: внутренним корпоративным документам, профильным базам, научным публикациям. Эти материалы добавляются к запросу, после чего модель создаёт точный и тематически сфокусированный ответ — без дообучения модели на новых данных.
Какие преимущества даёт RAG?
Экономичное внедрение и масштабирование ИИ
Организации часто запускают проекты с базовой моделью, обученной на открытых датасетах. Такие модели формируются на основе информации из публичных источников.
Адаптация под узкие задачи требует значительных ресурсов — как вычислительных, так и экспертных. Причём квалифицированные специалисты (часто уровня PhD) обходятся организациям дороже, чем оборудование. При настройке модель изменяет параметры, чтобы учитывать специфику области и выдавать точные ответы.
RAG подключает внутренние источники и увеличивает производительность без дообучения. Такой подход снижает нагрузку на инфраструктуру и упрощает масштабирование.
Обновляемые источники информации
При обучении генеративных моделей используются материалы, доступные до определённой даты. Поэтому такие модели не знают актуальных событий и данных. Использование внешних источников через RAG позволяет дополнять запрос актуальной информацией по соответствующей теме и получать более точные ответы.
Также применяются закрытые базы — например, архивы, исследования и другие материалы, недоступные в открытом доступе.
RAG-системы позволяют языковым моделям использовать информацию из социальных сетей, отзывов, новостей и поисковых платформ. Это расширяет контекст и делает ответы более точными.
Пример работы генерации с расширением через поиск (Retrieval-Augmented Generation)
На примере протокола совещания рассмотрим задачу поиска и ответа на основе стенограмм заседаний и публичных выступлений. Исходные данные — расшифровки встреч, преобразованные в протоколы. Такой формат фиксирует ход обсуждения и используется для анализа и семантического поиска.
Протокол содержит блоки: сведения об участниках, перечень тем повестки, содержание выступлений и зафиксированные решения с поручениями. При создании базы знаний блоки переносятся в отдельные таблицы и снабжаются векторными индексами, что даёт точный поиск по смыслу.
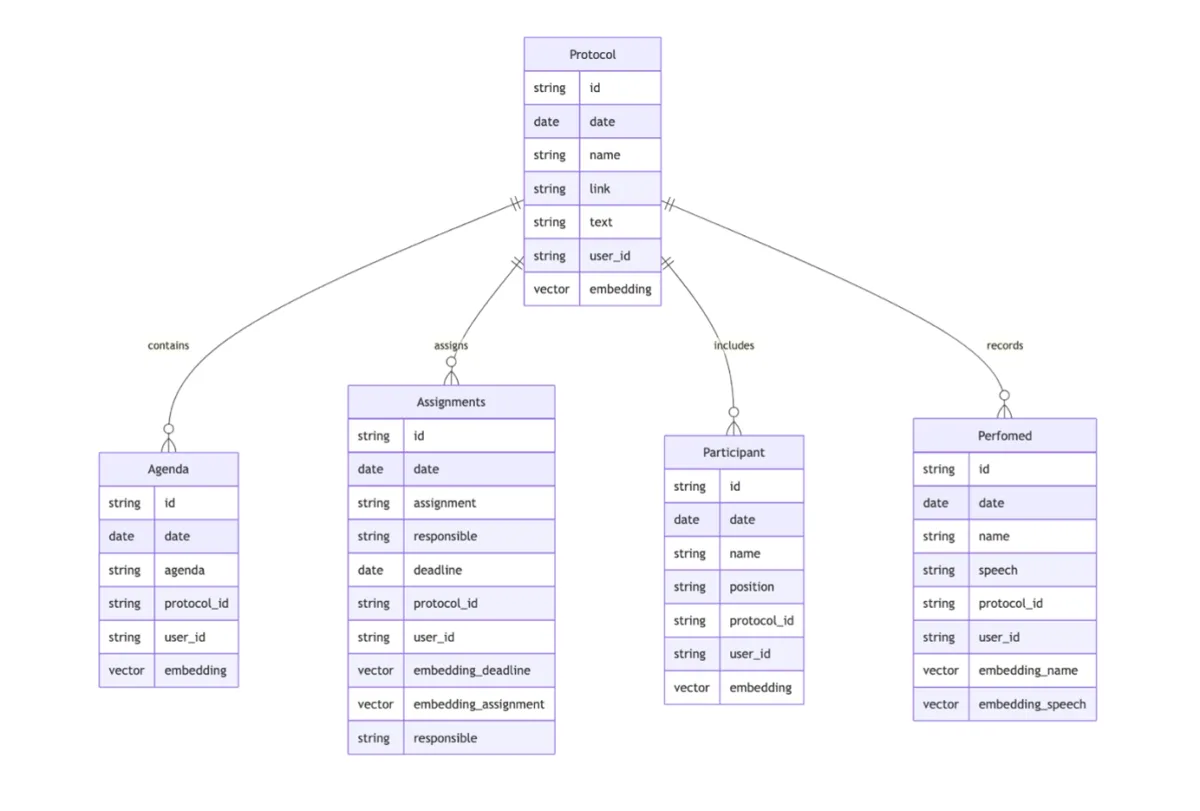
Пример модели данных разработанной RAG-системой
Такое разбиение на сущности даёт отдельный поиск по каждому типу информации и даёт возможность комбинировать результаты при формировании ответа. Длинные записи сопровождаются кратким резюме для векторного представления и метаданными (дата заседания, источник, участники). Это упрощает отбор и повторное ранжирование.
Дальнейшая обработка строится по принципу Retrieval-Augmented Generation. Запрос разбивается на части: уточняются формулировки, выполняется семантическое расширение, поиск по протоколам и повторное ранжирование. Например, на вопрос «Какие поручения выдали Минстрою по итогам совещания 5 июня» выделяются объект («поручения»), адресат («Минстрой») и контекст (дата заседания). Затем уточнённый запрос запускает отбор протокола по дате, поиск среди поручений и сортировку найденных вариантов по степени соответствия.
Финальный набор фрагментов передаётся в языковую модель, которая формирует связный ответ с опорой на исходные данные. Для генерации используется модель princeton-nlp/gemma-2-9b-it-SimPO, обученная по методу Simple Preference Optimization (SimPO). Модель выбирает удачные формулировки и сохраняет логическую последовательность.
Поддержание актуальности базы знаний
Чтобы модель продолжала использовать обновлённые сведения, векторные индексы пересчитываются автоматически при изменениях в базе. Это позволяет не терять связь с текущим содержанием и формировать ответы на основе актуальной информации, даже если основная модель не была дообучена (дополнительно обучена).
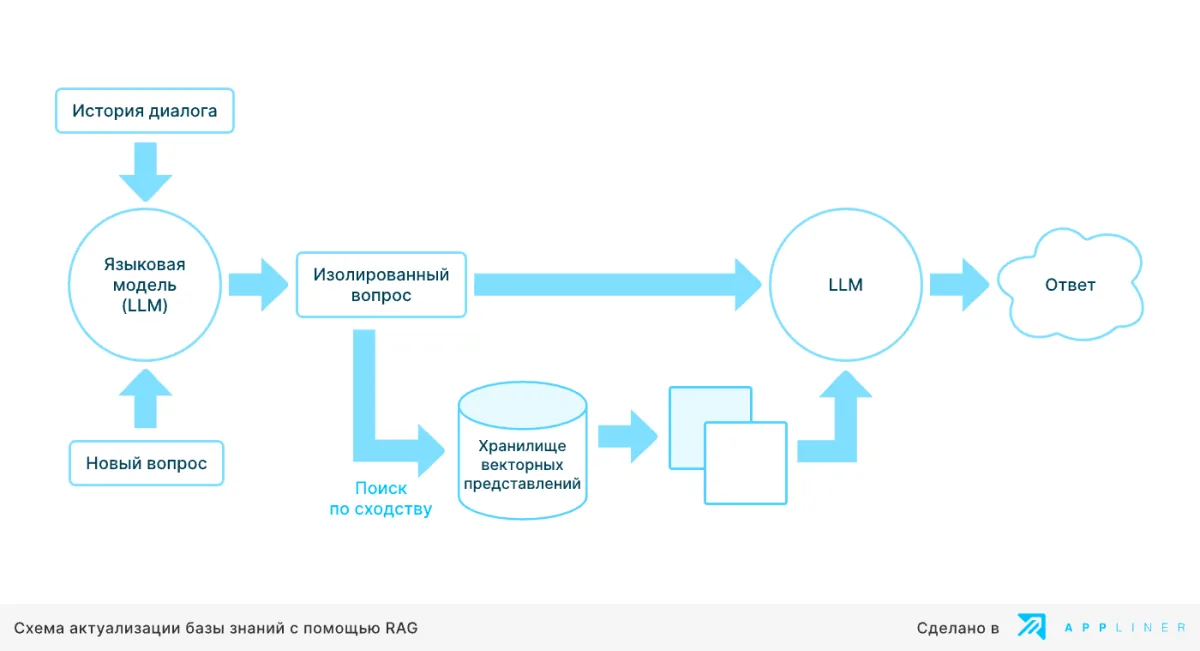
Пример вызова инструмента
• Пользователь спрашивает: «Какой сейчас курс доллара?»
• Языковая модель не подключена к актуальным источникам и не видит обновлений в момент запроса. Чтобы получить точный ответ, ей нужен внешний контекст.
• В этом случае система формирует запрос «курс доллара к рублю», извлекает значение из первого подходящего источника и добавляет его к вопросу. Языковая модель использует полученный контекст и формирует ответ.
Сценарий посложнее
• Допустим, требуется создать LLM-бота для техподдержки, а в наличии — база знаний с документацией и типовыми вопросами.
• Обучать модель на всей базе — не лучшее решение. Такой подход затратен и не учитывает регулярные изменения в источниках.
• Взамен применяется RAG: по запросу система находит релевантный материал, передаёт его (или часть) в модель, и та формирует ответ с учётом найденной информации.
О названии технологии
Фраза Retrieval-Augmented Generation чётко описывает процесс:
• Retrieval — поиск и ранжирование нужного материала в базе. Механизм называется retriever.
• Retrieval-Augmented — дополнение пользовательского запроса найденной информацией.
• Retrieval-Augmented Generation — генерация ответа с учётом извлечённого контекста.
На этом этапе закономерно возникает вопрос:
«Что тут сложного? Нашёл нужный фрагмент, добавил в контекст — и всё работает.»
Однако, как и в большинстве инженерных решений, ключевые сложности скрыты в деталях. Уже на старте реализации RAG-подхода появляются первые, казалось бы, очевидные препятствия. Ниже перечислены основные из них — те, с которыми чаще всего сталкиваются на практике.
1. Нечёткий поиск
Точное совпадение запроса с текстами базы знаний редко даёт результат. Нужен метод, извлекающий фрагменты по смыслу, а не по совпадению слов.
2. Размер фрагментов текста или документов
Необходимо определить оптимальный объём данных, который передаётся в модель. Слишком маленькие фрагменты теряют контекст, слишком большие — перегружают модель и снижают точность ответа.
3. Метод поиска и работа с источниками
Главная задача — находить именно релевантные материалы. Проблемы возникают, если найдено несколько статей или один крупный документ: такие тексты приходится обрезать или сжимать, чтобы сохранить суть и уложиться в лимиты модели.
4. Масштабирование
По мере роста числа документов точность поиска может падать. Если систему неправильно организовать, она будет извлекать нерелевантные данные, что напрямую снижает качество итоговых ответов.
Такие вопросы появляются уже в начале — даже при разработке базовой схемы. Сегодня существует рабочий подход, на котором строится решение. Его можно адаптировать под задачу и развивать поэтапно, превращая основу в полноценный инструмент.
Базовая архитектура RAG: как работает система
Стартовая конфигурация Retrieval-Augmented Generation (RAG) — это стандартный алгоритм, состоящий из нескольких этапов:
Создание базы знаний
1. Фрагментация базы знаний
База знаний разбивается на небольшие фрагменты текста — чанки. Размер каждого чанка варьируется: от нескольких строк до нескольких абзацев, то есть в диапазоне 100–1000 слов.
2. Генерация эмбеддингов
Каждый чанк обрабатывается с помощью специальной модели — эмбеддера — и преобразуется в векторное представление. Вектор отражает скрытое семантическое содержание текста. По нему можно выполнять поиск по смыслу.
3. Сохранение в базе эмбеддингов
Полученные вектора сохраняются в специализированной базе данных, предназначенной для поиска по векторным признакам. Эти вектора остаются в системе до тех пор, пока не поступит запрос.
Эксплуатация
4. Преобразование запроса пользователя
Когда пользователь задаёт вопрос, текст также преобразуется в эмбеддинг — обычно тем же эмбеддером, что применялся к чанкам. Затем запускается поиск по базе: вычисляется схожесть (например, косинусная близость) между вектором запроса и векторами чанков. Отбираются релевантные фрагменты.
5. Формирование входного контекста для LLM
Тексты найденных чанков объединяются с пользовательским запросом в единый контекст, который передаётся на вход языковой модели. Таким образом, LLM получает не только сам вопрос, но и связанные с ним данные.
6. Генерация ответа
На основе расширенного контекста языковая модель формирует итоговый ответ, который учитывает как запрос пользователя, так и извлечённую информацию из базы знаний.
Практические реалии запуска RAG-системы
Как видно из ранее описанного алгоритма, архитектура RAG не представляет сложности:
текст разбивается на чанки, каждый чанк преобразуется в вектор (эмбеддинг), система находит подходящие по смыслу фрагменты и передаёт их вместе с пользовательским запросом на вход языковой модели.
Большинство этапов уже реализовано в готовых решениях. Для запуска базовой версии RAG применяются пайплайны из специализированных библиотек.
Запуск первой версии показывает, что результат отличается от ожидаемого. Это инициирует следующий этап — настройку и оптимизацию RAG-систем для достижения нужного качества и стабильности ответов.
В следующем разделе представлены практические подходы и принципы, применяемые для повышения эффективности RAG-систем. Каждый раскрыт в отдельных материалах. Такой формат даёт чёткую структуру подачи без перегрузки одной публикации.
Размер чанков и объём контекста
Выбор подходящего размера текстовых фрагментов (чанков) и их количества — важный параметр, влияющий на результат генерации. Если модель получает мало данных, она может не уловить смысл запроса. Если контекст перегружен лишней информацией, точность ответа падает. Размер чанка — это компромисс между точностью поиска и полнотой охвата. Небольшие чанки лучше работают для буквального совпадения, крупные — для смыслового поиска. Объём информации должен подбираться динамически в зависимости от типа пользовательского запроса.
При этом простая нарезка текста не всегда эффективна. Более надёжный подход — извлечение сущностей и организация информации по соответствующим доменам. Такой метод позволяет системе работать не с разрозненными кусками, а со структурированными данными, где каждая сущность имеет своё место и связи. В ряде случаев полезно индексировать не только текст, но и изображения или табличные данные, что делает систему более универсальной.
Перекрытие чанков
Для сохранения логической последовательности стоит формировать чанки с перекрытием. Это позволяет передавать модели связный контекст, а не набор фрагментов. Перекрытие снижает риск потери информации на стыках и помогает сохранить целостность повествования.
Структурная целостность чанков
Начало и конец чанка должны совпадать с завершённой мыслью. Предпочтительно формировать чанки по границам предложений или абзацев. Такой подход исключает обрывы и повышает точность интерпретации.
Комбинирование методов поиска
Поиск по эмбеддингам — базовый инструмент, но он не всегда даёт оптимальный результат, особенно в областях со специализированной лексикой или техническими терминами. В таких случаях к векторному поиску добавляют TF-IDF или BM25, а затем объединяют результаты с учётом весов. Это увеличивает полноту и надёжность поиска.
Мультиплицирование запросов
Один и тот же вопрос можно сформулировать по-разному. Переформулированные варианты, полученные через LLM, расширяют охват и повышают вероятность нахождения релевантных данных. Обычно создают 3–5 вариантов запроса и объединяют результаты поиска.
Суммаризация чанков
Если найдено слишком много информации, которая не помещается в контекст, её можно сжать. LLM формирует краткую выжимку, сохраняя ключевой смысл. Такая «архивация» позволяет уместить данные в лимиты модели и при этом сохранить фактическую основу ответа.
Системный промпт и адаптация модели
Чтобы модель корректно обрабатывала данные, важно разделять вопрос и контекст. Это реализуется через системный промпт с заданным форматом: «сначала вопрос, затем информация для ответа». При необходимости модель дообучают на примерах именно такого взаимодействия, чтобы повысить устойчивость и снизить вероятность выдуманных ответов.
Оценка качества
Ключевая часть работы с RAG — постоянная проверка качества. Изменение размера чанков, замена эмбеддера или корректировка алгоритма поиска всегда отражаются на результатах. Проверять единичные ответы вручную бессмысленно: оценка должна быть масштабируемой.
Проверочные вопросы формируются вручную, так как именно команда или заказчик знают реальные сценарии. Референсные ответы также готовят специалисты, желательно несколько вариантов для одного вопроса, чтобы исключить субъективность. В ряде случаев можно использовать LLM для генерации черновиков, но проверка должна оставаться за людьми.
Затем применяются метрики качества: BERTScore, BLEURT, METEOR, ROUGE и их комбинации. Итоговый показатель формируется с весовыми коэффициентами, подобранными под задачу.
Особое внимание уделяется работе ретривера: именно качество найденных фрагментов определяет до 80% итогового результата. Поэтому вместе с тестовыми вопросами формируют эталонные чанки, и при каждой настройке системы оценивается, насколько точно ретривер извлекает нужные данные.
На этом всё — надеемся, материал помог вам разобраться, как работает генерация ответов с дополненной выборкой (RAG) на примере протокольных данных, и вдохновил на новые идеи применения этой технологии. Следите за релизами, новостями и кейсами внедрения — присоединяйтесь к сообществу Appliner в Телеграм.



Оставить комментарий