
Введение
В гонке за новое поколение ИИ большие языковые модели (LLM) начинают брать на себя новые роли. Один из примеров — LLM-as-a-Judge: система, которая оценивает работу людей или других языковых моделей.
Такой подход экономит сотни человеко-часов асессоров. Но встаёт вопрос: способна ли LLM проверять качество на уровне эксперта и замечать тонкие недочёты? И что происходит в сферах, где важную роль играют интуиция и отраслевые компетенции? Профессиональные асессоры обладают высоким уровнем экспертизы в своей предметной области, недоступным ИИ. Поэтому всё чаще используют комбинированный подход: LLM помогает быстро отсеять очевидные ошибки и сэкономить время, а финальную оценку даёт эксперт. В статье разберём, что такое LLM-судья, как его оценка соотносится с экспертной и почему комбинированный подход даёт лучший результат.
Что такое «LLM as a judge»?
«LLM as a judge» — подход, при котором результаты работы оцениваются не людьми напрямую, а через большие языковые модели. Подход используют для проверки ответов других AI-моделей, работы ассесоров или отдельных метрик.
Модели вроде GPT-5 выполняют роль судей: выдают повторяемые оценки с предсказуемыми результатами при одинаковых условиях.
AI-команды применяют LLM-судей для предварительной проверки: модели фиксируют очевидные успехи и ошибки до подключения экспертов. Это сокращает процесс оценки в задачах разметки и анализа качества сгенерированного кода.
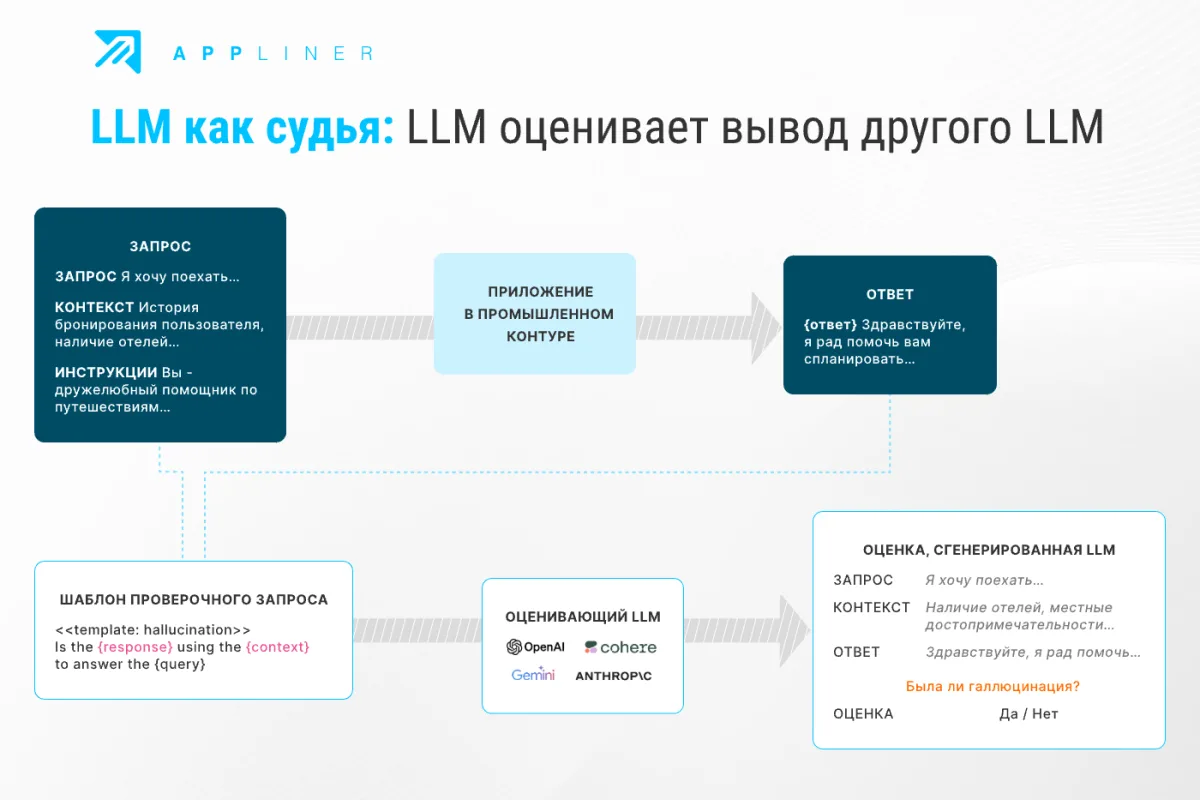
Как работает LLM-as-a-Judge
В оценочном контуре LLM-as-a-Judge проверяющим выступает отдельная модель: оценивает результаты других моделей, выставляет баллы по заданной шкале, проверяет учебные материалы и помогает сравнивать решения по единым критериям.
Базовая настройка строится на четырёх шагах, но самое первое — совместно с экспертами определить набор критичных метрик и целевые пороги. Именно они задают рамку всей последующей оценки.
- Определить. Сформулировать задачу оценки: указать объект и цели проверки; зафиксировать вместе с экспертами критичные метрики и их веса/пороги (связность, соответствие инструкции, точность фактов, релевантность и др.).
- Сконструировать промпт(ы). Задать роль судьи, правила и шкалу, формат ответа и требования к пояснению вердикта; описать критерии единообразия; добавить параметры, уменьшающие смещение. При необходимости использовать цепочку промптов, которая по каждой метрике отдельно оценивает исходные данные.
- Предъявить материал. Подготовить входы и варианты ответов; привести их к единому формату, чтобы модель корректно сопоставляла запросы и результаты.
- Верифицировать и проанализировать. Когда прототип готов, сравнить его оценки с экспертными/«золотыми» эталонами, откалибровать шкалы и подправить промпты. Свести итоговые метрики, отметить улучшения/регрессии, сделать вывод. Если пороги пройдены — запуск в эксплуатацию, если нет — цикл доработки повторяется.
Далее раскрываются детали каждого этапа.
Определение задачи оценки
Первый шаг — чётко сформулировать задачу, в которой LLM выступает судьёй. Нужно определить тип контента или результата, подлежащего оценке. Например, это может быть проверка качества письменных ответов, точности информации, сравнение нескольких результатов или выставление итоговой оценки по заданным критериям.

Определение задачи — это фундамент для всех последующих шагов в процессе оценки с помощью LLM. Ниже приведены примеры формулировок задач:
Единая шкала 1–5
5 — полностью соответствует; 4 — мелкие недочёты; 3 — заметные проблемы; 2 — существенные; 1 — критические.
Агрегация по умолчанию: среднее; при critical_issues — overall ≤ 3.
1) Pointwise (один текст)
Метрики:
- Ясность: понятность при первом чтении, отсутствие двусмысленностей/необъяснённых терминов.
- Беглость: грамматика, орфография, естественность.
- Связность: логичная структура и переходы.
Промпт (вставка):
Оцени текст по метрикам выше, без внешних знаний. По каждой из метрик дай краткое обоснование (≤20 слов). Вывод в JSON.
JSON:
{
«clarity»: {«score»: 1-5, «reason»: «…»},
«fluency»: {«score»: 1-5, «reason»: «…»},
«coherence»: {«score»: 1-5, «reason»: «…»},
«critical_issues»: [],
«overall»: {«score»: 1-5}
}
2) Два резюме одной статьи (оценка → выбор)
Метрики:
- Coverage: охват ключевых пунктов исходника.
- Faithfulness: отсутствие искажений/домыслов.
- Conciseness: краткость без потерь.
- Structure: порядок и переходы.
- Readability: лёгкость чтения.
Правила: сначала оцени каждое резюме против исходника; затем выбери. При равенстве — приоритет faithfulness, потом coverage. Критические искажения → winner: «none».
JSON:
{
«summary_A»: {
«coverage»: {«score»: 1-5, «reason»: «…»},
«faithfulness»: {«score»: 1-5, «reason»: «…»},
«conciseness»: {«score»: 1-5, «reason»: «…»},
«structure»: {«score»: 1-5, «reason»: «…»},
«readability»: {«score»: 1-5, «reason»: «…»},
«total»: 0.0,
«critical_issues»: []
},
«summary_B»: { /* то же */ },
«decision»: {«winner»: «A|B|none», «tie_breaker»: «faithfulness|coverage|none», «justification»: «≤25 слов»}
}
3) Машинный перевод (MT)
Метрики:
- Adequacy: полнота и точность смысла, без пропусков/добавлений.
- Fluency: естественность и грамотность языка.
- Terminology/Style: корректные термины, единый стиль.
Критические искажения → overall ≤ 2.
JSON:
{
«adequacy»: {«score»: 1-5, «reason»: «…»},
«fluency»: {«score»: 1-5, «reason»: «…»},
«terminology_style»: {«score»: 1-5, «reason»: «…»},
«critical_errors»: [],
«overall»: {«score»: 1-5, «justification»: «≤25 слов»}
}
Проектирование оценочного промпта
Следующий шаг — разработать промпт для LLM. Эффективный промпт повышает точность оценки и снижает риск появления предвзятости.
Ключевые компоненты для сильных оценочных промптов
• Контекст задачи (что именно проверяется): объясняется сценарий и цель.
Пример: «Ты выступаешь как экзаменатор по английскому языку. Твоя задача — оценить письменный ответ ученика на грамматику и лексику».
• Критерии оценки (по каким признакам судить): фиксируются параметры качества.
Пример: «Оцени по шкале от 1 до 5 за: точность фактов, связность, соответствие инструкции».
• Формат ответа (как вернуть результат): указывается нужный формат.
Пример: «Верни один балл от 1 до 5 и короткое пояснение в одном предложении».
• Дополнительные данные (на что опираться): при необходимости подключаются материалы.
Пример: «Используй предоставленный референсный перевод как эталон для сравнения».
Оценка ответа
LLM анализирует представленный материал по заданным критериям и выносит решение в трёх форматах.
Оценка: количественная оценка одним числом (обычно 0-100 или 1-10), рассчитанная как среднее, чаще взвешенное, по критериям. К числу при необходимости добавляется короткое объяснение: что потянуло оценку вверх/вниз и почему.
Классификация: отнесение к категориям по заранее заданным порогам тех же критериев. Используются два среза: качество (Плохо — 0–59, Средне – 60-79, Хорошо — 80–100) и релевантность/полезность (Горячо — релевантность ≥ 70, Холодно — иначе). Для каждого среза при желании добавляется краткое пояснение причин.
Рассуждение: компактное текстовое объяснение (1-3 предложения), которое фиксирует ключевые сильные стороны, главные пробелы и конкретную рекомендацию по доработке.
Как применять: задать критерии и их веса (по умолчанию равные), проставить баллы 0-100 по каждому с короткими комментариями, посчитать итог по шкале и присвоить классы по порогам, затем дать резюме, которое переводит оценку в понятное действие (публиковать, доработать, отклонить).
Оценка LLM-судьи
Заключительный этап — проверка самого оценочного контура и выставление «оценки» LLM-судье. Напоминание: на всех предыдущих стадиях присутствует человеческое участие. Сопоставляются суждения модели с человеческими оценками или иными эталонами, чтобы измерить качество и точность. Возможные исходы два: 1) переход в производство при успешном прохождении проверки; 2) возврат на доработку при неудовлетворительных результатах.
Способы структурирования промпта и проведения оценки зависят от цели. Базовые стратегии — две:
• Парное сравнение (Pairwise Comparison): предъявляются два ответа, требуется определить, какой вариант лучше; подходит для сопоставления моделей, промптов или конфигураций.
• Оценка одного ответа (Pointwise): анализируется одиночный ответ с присвоением балла для измерения отдельных качеств, таких как тон, ясность и корректность.
Дополнение: обе техники совместимы с промптингом в стиле chain of thought (CoT) для повышения качества оценивания.
Повышение эффективности LLM как судьи
Инженерные практики повышают результативность LLM в роли судьи. Один из подходов — Chain-of-Thought (CoT) prompting. LLM формулирует рассуждения по шагам. Такой формат делает ответы прозрачными и повышает точность.
Основные элементы:
- Чёткие инструкции в промпте: контекст задачи, критерии оценки и формат вывода.
Подходы CoT:
- Zero-Shot CoT: в запрос добавляется строка «Напишите пошаговое объяснение оценки». Модель раскрывает ход рассуждений.
- Few—Shot-CoT: специалист формирует шаги которые должна пройти LLM для успешной оценки.
Дополнительные стратегии:
- Few-shot learning: модели показывают несколько примеров оценок (с ответами, рубриками, диалогами), чтобы уточнить критерии.
- Iterative refinement: результаты LLM-судьи анализируются регулярно, промпты корректируются для повышения точности и стабильности.
- Structured output: для унификации оценок применяется строгий формат вывода с заданными полями, например YML, JSON или XML.
Важность согласования с человеческой оценкой в LLM-as-a-judge
Использование LLM в роли судей решает проблему масштабируемости и стоимости человеческой оценки. Но ключевым условием остаётся согласованность (alignment) — степень, в которой суждения модели коррелируют с человеческими.
Почему alignment критичен:
- Надёжность: цель — не просто автоматизация, а создание достоверного прокси для человека. Без корреляции с человеческими оценками результаты теряют практическую цнность.
- Диагностика слабых мест: сопоставление выводов LLM с оценками экспертов выявляет системные ошибки и уязвимости модели.
- Улучшение моделей: знание предвзятостей позволяет корректировать их. Исследования OpenAI показывают: применение RLHF (обучение с подкреплением через обратную связь от людей) повышает согласованность до 30%.
- Валидация подхода: если LLM не воспроизводит суждения людей, её ценность как автоматического судьи сомнительна.
Важно: alignment — это не совпадение численных баллов, а способность LLM воспроизводить устойчивые и надёжные оценки, приближенные к экспертным.
Проблемы LLM-as-a-Judge
Метод сталкивается с ограничениями:
- Качество данных: модели опираются на паттерны текста, а не на смысловое понимание. Ошибки в обучающих данных приводят к сбоям.
- Культурный контекст: LLM затрудняются при вопросах, требующих локальных знаний.
- Непоследовательность: в сложных кейсах возможны разные ответы при небольших изменениях промпта.
- Предвзятость: искажения, унаследованные из обучающих данных, включая эффект «самоусиления», когда модель выше оценивает собственные ответы.
- Стоимость и масштабируемость: при равных задачах работа LLM обходится дешевле и быстрее экспертной оценки.
- Надзор: даже сильные LLM-судьи требуют финальной проверки. Автоматическая оценка надёжна в типовых кейсах, но в сложных сценариях участие человека остаётся необходимым.
Человек в системе оценки
Человеческая проверка остаётся стандартом качества. Эксперт адаптируется к размытым инструкциям, уточняет критерии и фиксирует сбои модели.
Дженсен Хуанг сформулировал это так:
«Пока подход сохраняет смысл — человек остаётся в контуре. AI не обучается и не меняется без контроля. Сначала собираются данные, переносятся в модель, проводится обучение, тестирование и валидация. После этого модель снова используется. Поэтому человек в контуре необходим».
Вместе лучше: LLM-as-a-judge + human-in-the-loop
При первичной проверке LLM отсекает результаты, не требующие анализа. Эксперт работает со сложными кейсами. Такой формат распределяет задачи и уменьшает число ошибок.
AI-команды применяют двухуровневую схему:
• LLM для охвата: помечает подозрительные данные и формирует обратную связь.
• Эксперт для глубины: выносит финальную оценку в спорных случаях и уточняет критерии.
Обучение на корректировках делает модель точнее в роли судьи.
Чем еще полезна LLM-as-a-judge на практике?
В компаниях трудно проверять качество работы отдела продаж вручную. Сотни звонков остаются без анализа, хотя разговоры показывают, почему сделки срываются или закрываются. Решением становится LLM-as-a-Judge — языковая модель, которая оценивает звонки менеджеров по заданным критериям.
Модель анализирует каждый разговор, а не выборочно. Руководитель задаёт параметры: приветствие, выявление потребностей, работа с возражениями, аргументация, завершение диалога. Искусственный интеллект фиксирует сильные и слабые стороны общения и выставляет оценку по этим параметрам.
Такой подход делает оценку массовой и объективной. Разговоры проверяются по единым правилам, без человеческого фактора. Для бизнеса это значит полная аналитика: видно, кто из сотрудников работает лучше, а кому нужно обучение. На основе отчётов легко строить планы развития и подбирать примеры практик.
LLM-as-a-Judge снимает рутину с руководителей, даёт чёткую оценку, сохраняет стандарты и помогает развивать сотрудников даже при сокращении команды. В итоге компания получает не «оценку звонков», а инструмент управления отделом, который напрямую влияет на результат.
Как создать LLM-as-a-judge
Построение эффективной системы «LLM-as-a-judge» не обязательно должно быть сложным, но есть несколько ключевых шагов, о которых следует помнить:

Выбор модели
Начните с производительной LLM, например модели OpenAI GPT-5, o3. Для доменных задач используйте дообучение или специализированные модели.
Определение критериев оценки
Чётко зафиксируйте, что считается «правильным». Например, в задаче анализа тональности — описать каждую категорию и привести примеры. Это снижает долю догадок со стороны модели.
Проектирование промтов и примеров
LLM работает лучше при корректно заданных инструкциях. Добавьте образцы правильных и ошибочных ответов, чтобы модель понимала, на что ориентироваться.
Порог неопределённости
Определите метрику или логику, по которой модель может сказать «не уверена». Такие случаи передаются на проверку человеку.
Сбор обратной связи и итерации
Отслеживайте, где модель справляется, а где ошибается. На основе этого улучшайте промты, обновляйте модель или корректируйте гайдлайны.
Мониторинг дрифта
Модели могут деградировать при изменении данных (Stanford CRFM). Регулярно проверяйте качество работы, чтобы не допустить снижения точности.
Итог
LLM-as-a-judge не заменяет эксперта. Модель берёт на себя рутинные и объёмные задачи, сокращает время обработки и передаёт эксперту сложные кейсы. Скорость LLM в связке с глубиной анализа человека даёт отбор ошибок, контроль спорных ситуаций и равномерное качество данных. Такой формат помогает командам строить AI-системы, выдерживать сроки и сохранять единые стандарты на этапах проекта.



Оставить комментарий